一个 Twitter 的负载例子
Contents
两个 Twitter 的典型操作:
- 发布
tweet:用户可以快速推送新消息到所有关注者,平均4.6k request/sec,峰值约12k request/sec; - 主页时间线(Home timeline)浏览:平均
300k request/sec查看关注对象的最新消息;
普通思路
将新发的 tweet 插入到全局 tweets 集合中。当用户查看时间线,先查找所有该用户关注的所有关注对象,根据时间排序,合并所有关注对象的消息。SQL 如下:
SELECT tweets.*, users.* FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user_id
难点:每个用户会关注很多人,也会被很多人关注。采用传统的多表 join 查询在后续中的读取中必然的会造成对 tweets 表的巨大压力:维护 sender_id 列的索引也是一个巨大的成本,且区分度可预见性的不会太高,这就导致以上查询会扫描表的大部分行。
增加一个缓存
对每个用户维护一个时间线缓存,如下图所示,
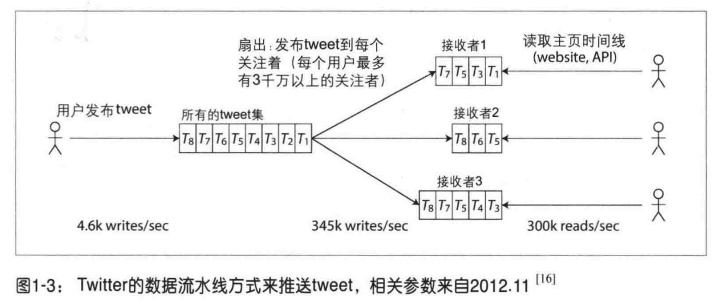
用户新发 tweet 消息,查询关注者,将 tweet 插入到关注者的时间线缓存中。
给每一个用户维护一个队列,因为已经预先给每个用户将结果取出,访问的时候性能将会得到一定的保障;
一些结论
方法 1 进行全表的查询,读的压力会很大;
通过方法 2,在发布的时候多做一些工作,来减少读的压力;
说一下 Twitter 最后的做法,方法 2 被稳定实现,但是 Twitter 倾向于结合两种方法。
-
大多数普通用户(关注者不是超级数量级的)新发
tweet消息采用第2种方法, -
针对超多关注者的用户,使用方法
1,其推文被单独提取,根据用户的关注列表,在读取时与用户的时间线进行合并。
还有手段可以完成,进行优化:
- 根据用户的关注对象数量采取不同的推送策略;
- 针对关注对象特别多的用户的时间线,采用延时消息进行推送;
- 优先保证超多关注者的用户推送准确性;
- …
一个细微的小观察,会发现,无论是